Einfaktorielle Varianzanalyse (mit Messwiederholung)
Seiteninhalt
- Quick Start
- 1. Einführung
- 1.1. Beispiele für mögliche Fragestellungen
- 1.2. Voraussetzungen der einfaktoriellen Varianzanalyse mit Messwiederholung
- 2. Grundlegende Konzepte
- 2.1. Beispiel einer Studie
- 2.2. Die Grundidee der Varianzanalyse
- 2.3. Berechnung der Teststatistik
- 3. Die einfaktorielle Varianzanalyse mit Messwiederholung mit SPSS
- 3.1. SPSS-Befehle
- 3.2. Mauchly-Test auf Sphärizität
- 3.3. Ergebnisse der einfaktoriellen Varianzanalyse mit Messwiederholung
- 3.4. Post-hoc-Tests
- 3.5. Profildiagramm
- 3.6. Berechnung der Effektstärke
- 3.7. Eine typische Aussage
Quick Start
Wozu wird die Varianzanalyse mit Messwiederholung verwendet? Einfaktorielle Varianzanalyse mit Messwiederholung (SAV, 790 bytes) |
1. Einführung
Die einfaktorielle Varianzanalyse mit Messwiederholung testet, ob sich die Mittelwerte mehrerer abhängiger Gruppen (oder Stichproben) unterscheiden.
Die einfaktorielle Varianzanalyse mit Messwiederholung stellt eine Verallgemeinerung des t-Tests für abhängige Stichproben (oder Gruppen) für mehr als zwei Gruppen dar. Der Begriff "Varianzanalyse" wird wie bei allen Varianzanalysen oft mit "ANOVA" abgekürzt, da sie in Englisch "Analysis of variance" bezeichnet wird.
Von "abhängigen" Stichproben (oder Gruppen) wird gesprochen, wenn ein Messwert in einer Stichprobe und ein bestimmter Messwert in einer anderen Stichprobe sich gegenseitig beeinflussen. In drei Situationen ist dies der Fall:
- Messwiederholung: Die Messwerte stammen von der gleichen Person, zum Beispiel bei einer Messung vor einem Treatment, während einem Treatment und nach einem Treatment oder wenn verschiedene Treatments auf die gleiche Person angewandt werden und verglichen werden sollen.
- Natürliche Paarungen: Die Messwerte stammen von verschiedenen Personen, welche irgendwie zusammengehören (z.B.: Ehefrau – Ehemann – Paartherapeut, Psychologe – Patient – Angehörige, Anwalt – Klient – Richter – Kläger).
- Matching: Die Messwerte stammen von verschiedenen Personen, die einander zugeordnet wurden, zum Beispiel aufgrund eines vergleichbaren Werts auf einer Drittvariablen (die nicht im Zentrum der Untersuchung steht).
Mittels einer Varianzanalyse mit Messwiederholung können – obwohl der Name sich explizit auf Messwiederholungen bezieht – alle drei Typen von abhängigen Daten untersucht werden, also auch natürliche Paarungen oder einander zugeordnete Personen. Im Fokus der Analyse stehen die Unterschiede zwischen den jeweils verbundenen Messwerten. Oft wird ein Verlauf über die Zeit untersucht: Es wird zum Beispiel zu verschiedenen Zeitpunkten während eines Treatments (z.B. eine Diät, eine Therapie) dessen Erfolg gemessen (z.B. eine Gewichtsreduktion, Depressionswerte). Die Varianzanalyse betrachtet nun die Veränderung innerhalb der Personen und prüft, ob sich die Messzeitpunkte signifikant unterscheiden. Die Unterschiede zwischen den Personen sind dabei von untergeordneter Bedeutung.
Die einzelnen Messzeitpunkte werden gelegentlich als "Faktorstufen" oder "Treatments" bezeichnet, besonders wenn nicht eine Entwicklung über die Zeit, sondern lediglich ein Vergleich der Messungen das Ziel ist. Dies ist beispielsweise der Fall, wenn verschiedene Prognosemethoden der Krankheitsdauer miteinander verglichen werden. Entsprechend wird bei einer Messwiederholung auch von einem "Faktor" gesprochen. Als "einfaktoriell" wird eine Varianzanalyse mit Messwiederholung bezeichnet, wenn sie lediglich einen Faktor, also einen Messwiederholungs-Faktor, verwendet (vgl. "Hinweis: Mehrfaktorielle Varianzanalyse ohne Messwiederholung").
Die Fragestellung der einfaktoriellen Varianzanalyse mit Messwiederholung wird oft so verkürzt: "Unterscheiden sich die Mittelwerte einer abhängigen Variable zwischen mehreren abhängigen Gruppen, resp. Messzeitpunkten?"
1.1. Beispiele für mögliche Fragestellungen
- Wie verändert sich das Körpergewicht im Verlaufe einer 4-wöchigen Trennkostdiät? Dabei wird das Körpergewicht vor der Diät und am Ende jeder Diätwoche erhoben.
- Wie wirken sich drei verschiedene Therapien (Nikotinpflaster, Hypnose, Verhaltenstherapie) auf Nikotinsucht bei Kettenrauchern aus, wobei jeder Proband nacheinander jede Therapie ausprobiert?
- Wie verändern sich die Verkaufszahlen eines Produkts nach der Schaltung eines Werbespots im Regionalfernsehen? Die Verkaufszahlen werden dabei vor der Ausstrahlung, kurz danach, sowie 2 und 4 Monate danach erhoben.
1.2. Voraussetzungen der einfaktoriellen Varianzanalyse mit Messwiederholung
| ✓ | Die abhängige Variable ist intervallskaliert |
| ✓ | Die abhängige Variable ist normalverteilt innerhalb jedes Messzeitpunktes (Ab > 25 Probanden pro Messzeitpunkt sind Verletzungen in der Regel unproblematisch) |
| ✓ | Sphärizität ist gegeben (Mauchly-Test auf Sphärizität) |
2. Grundlegende Konzepte
2.1. Beispiel einer Studie
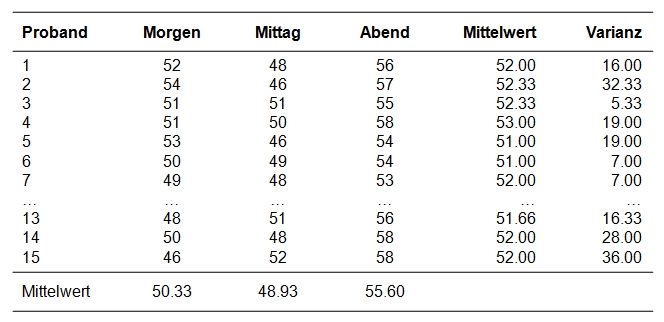
Der Zusammenhang zwischen der Tageszeit und der Konzentrationsfähigkeit soll untersucht werden. Dafür bearbeiten 15 Personen dreimal einen Konzentrationstest: morgens, mittags und abends. Verändert sich die Konzentrationsfähigkeit im Tagesverlauf?
Der zu analysierende Datensatz enthält neben einer Probandennummer (Proband) die drei Messungen der Konzentrationsfähigkeit (Morgen, Mittag, Abend). Damit beinhaltet er also pro Person eine Zeile und pro Messwiederholung eine Spalte (Variable).
2.2. Die Grundidee der Varianzanalyse
Ein Blick auf die Mittelwerte der Messzeitpunkte in Abbildung 1 zeigt, dass sich diese unterscheiden. Um zu überprüfen, ob die Unterschiede signifikant sind, wird eine Varianzanalyse mit Messwiederholung durchgeführt.
Die Grundidee der Varianzanalyse ohne Messwiederholung (siehe einfaktorielle Varianzanalyse, mehrfaktorielle Varianzanalyse) findet sich hier in einer angepassten Version wieder. Wie bei jeder Varianzanalyse wird auch hier versucht, die Abweichungen der individuellen Werte vom Gesamtmittelwert zu erklären. Als Mass für die zu erklärenden Abweichungen werden im Rahmen der einfaktoriellen Varianzanalyse mit Messwiederholung alle individuellen Abweichungen vom Gesamtmittelwert quadriert und aufsummiert. Dies führt zur Gesamtquadratsumme SStotal (da engl. "Sum of Squares"):
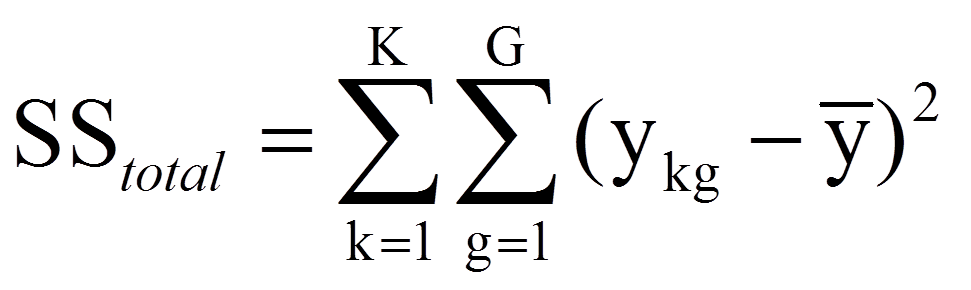
mit
|
|
= | Laufindex der Personen (hier: K = 15 Personen) |
|
|
= | Laufindex der Messwerte einer Person, G = Anzahl Messwerte (hier: G = 3 Messwerte) |
|
|
= | Gesamtmittelwert (über alle Personen und Messzeitpunkte hinweg) (hier: über alle 3 x 15 Werte hinweg) |
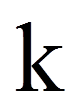
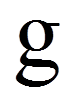
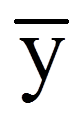
Diese Quadratsumme wird im Rahmen der einfaktoriellen Varianzanalyse mit Messwiederholung in zwei Teile zerlegt: Ein Teil der Quadratsumme ist durch die Unterschiedlichkeit der untersuchten Personen bedingt und ein Teil geht aus Veränderungen innerhalb der Person hervor. Das erstere ist die Quadratsumme zwischen den Personen SSzwischen Personen und basiert auf dem Unterschied zwischen dem Mittelwert einer Person (über alle Messzeitpunkte) und dem Gesamtmittelwert:
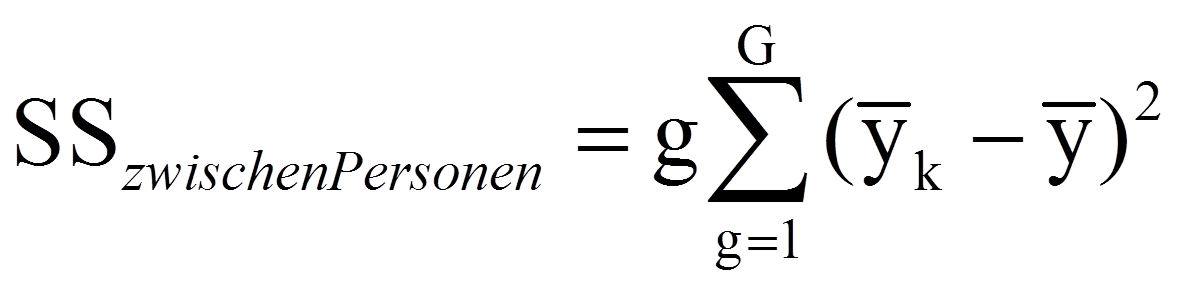
Der zweite Anteil ist die Quadratsumme innerhalb der Personen SSinnerhalb Personen und basiert auf den individuellen Abweichungen der unterschiedlichen Messzeitpunkte vom jeweiligen persönlichen Mittelwert:
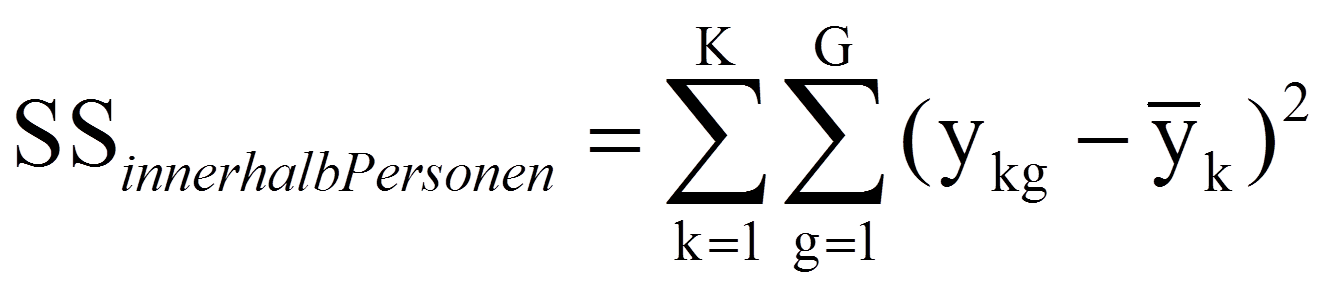
Diese Variation innerhalb der Personen (SSinnerhalb Personen) wird noch weiter aufgeteilt in einen Anteil, der dem Treatment (der Messwiederholung) zugeschrieben wird, und einen Residualwert, der nicht erklärt werden kann:
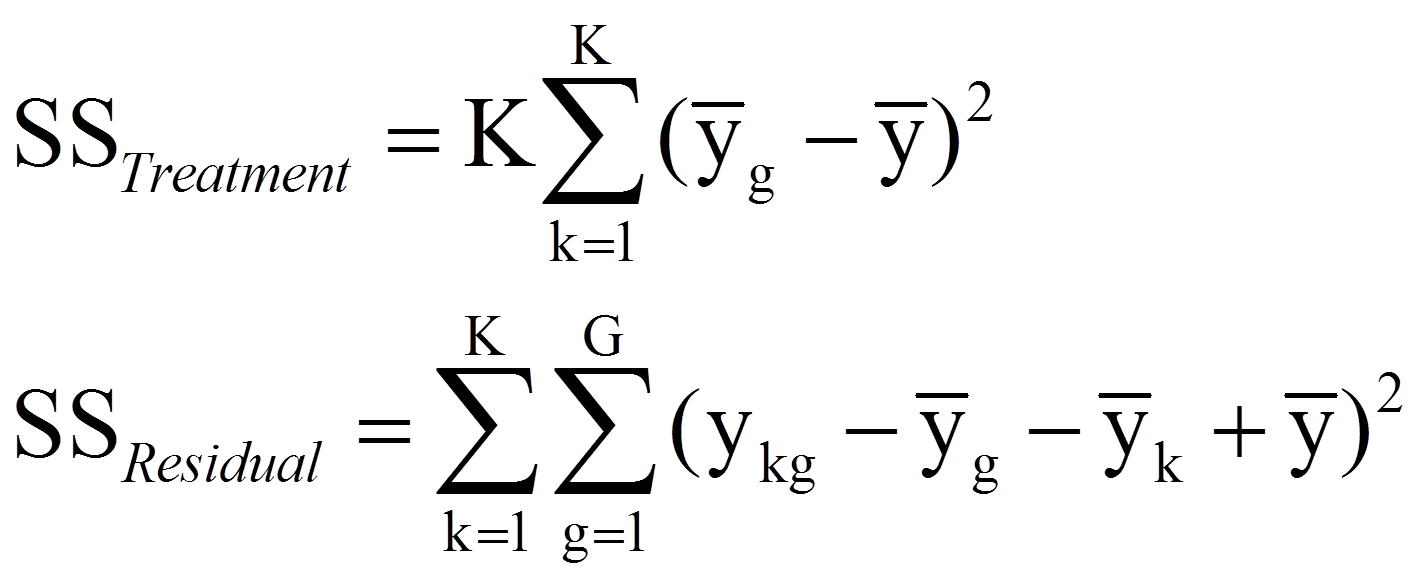
Damit gilt:
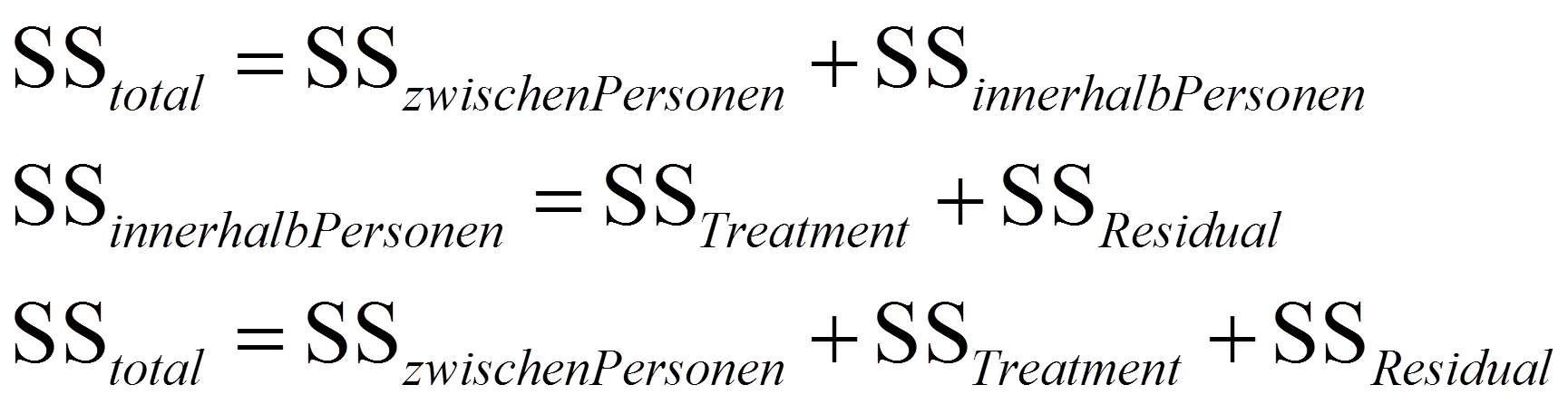
2.3. Berechnung der Teststatistik
Berechnen der Teststatistik
Zur Berechnung der Teststatistik F werden die mittleren Quadratsummen MSTreatment und MSResidual benötigt ("MS" da engl. "mean squares"). Die Quadratsummen werden dazu durch ihre jeweiligen Freiheitsgrade dividiert:
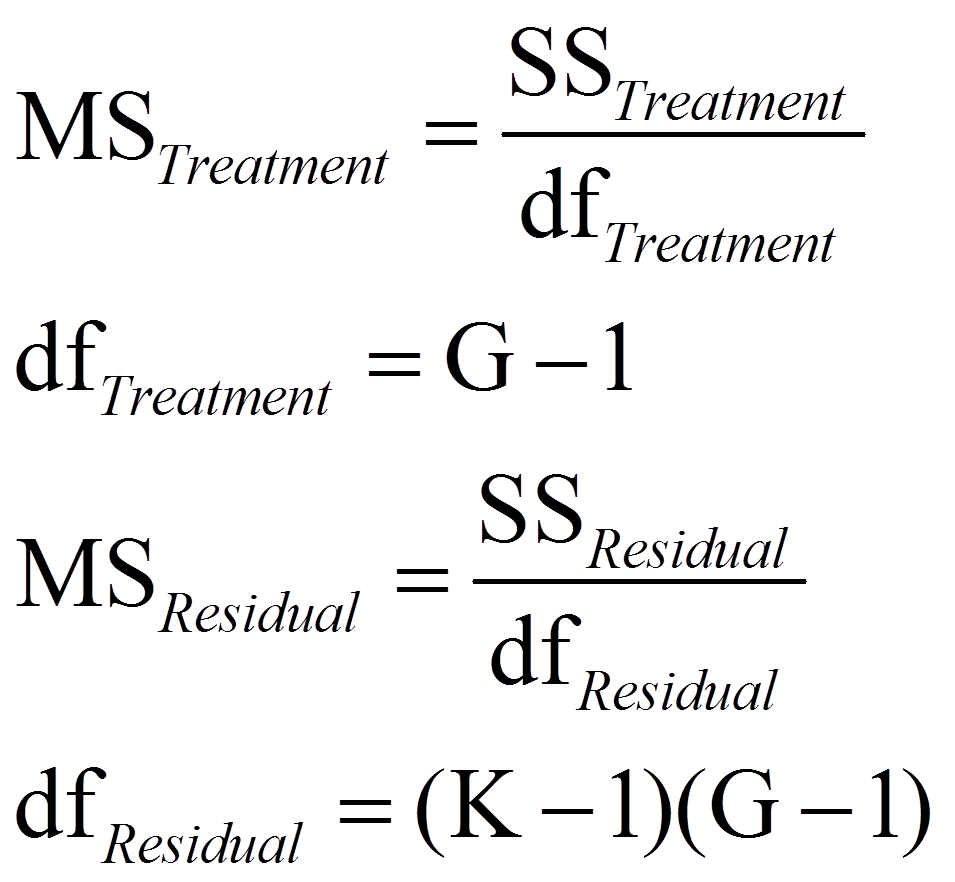
mit
|
|
= | Stichprobengrösse (hier: 15 Personen) |
|
|
= | Anzahl Messzeitpunkte (im obigen Beispiel: G = 3; da drei Messzeitpunkte) |
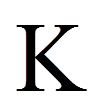
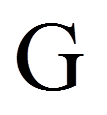
Anschliessend wird die Teststatistik F folgendermassen berechnet:
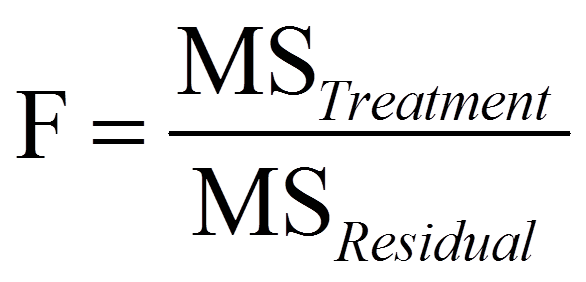
Signifikanz der Teststatistik
Je mehr Variation durch die Messwiederholung erklärt wird, desto höher fällt der F-Wert aus (da MSTreatment ein Mass für erklärte Varianz darstellt, während MSResidual ein Mass für Residualvarianz darstellt). Dieser F-Wert wird mit dem kritischen Wert auf einer durch die Freiheitsgrade dfTreatment und dfResidual charakterisierten F-Verteilung verglichen. Ist der F-Wert höher als der kritische Wert, so ist der Test signifikant.
3. Die einfaktorielle Varianzanalyse mit Messwiederholung mit SPSS
3.1. SPSS-Befehle
SPSS-Menü: Analysieren > Allgemeines Lineares Modell > Messwiederholung
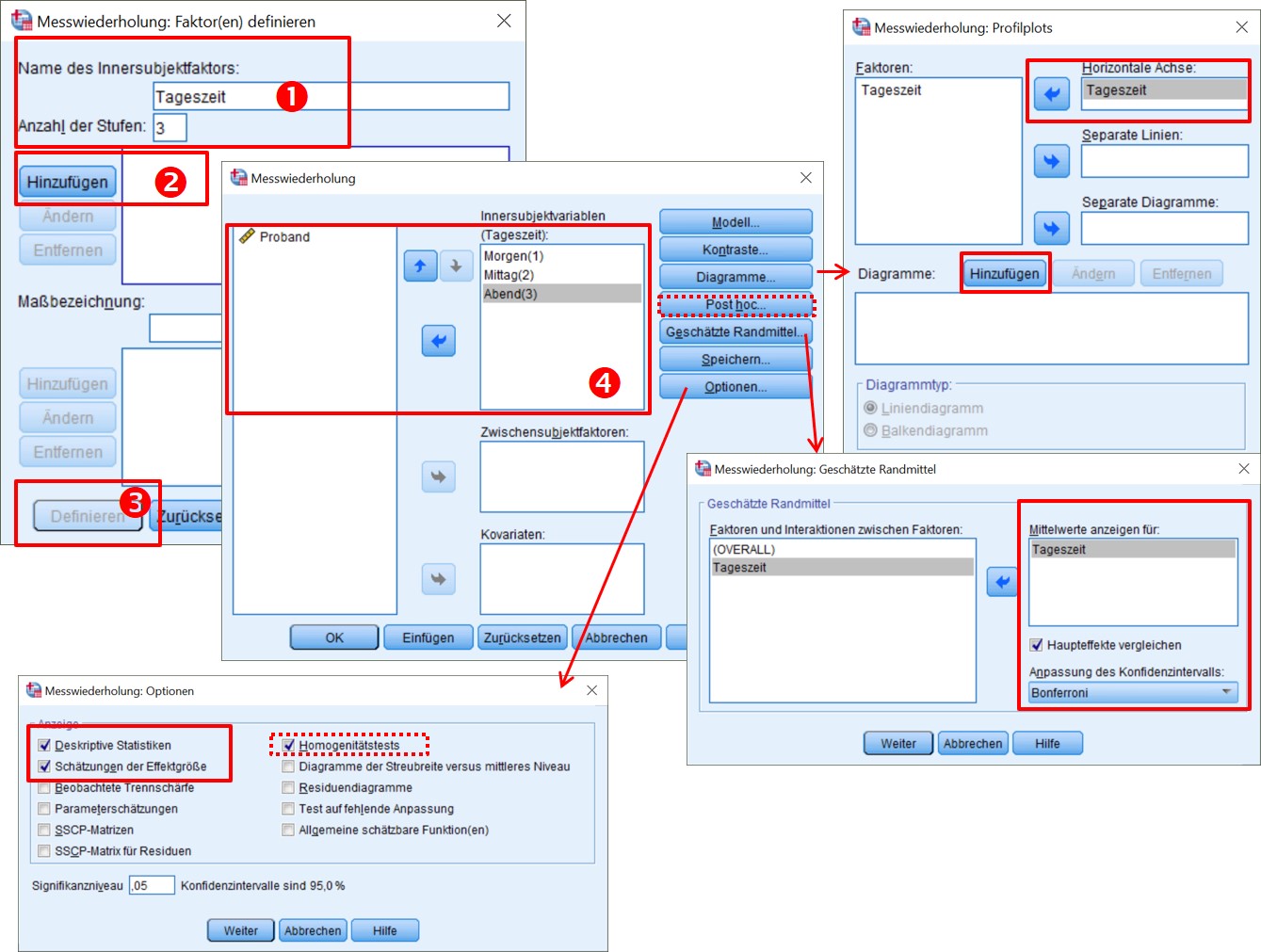
Hinweise
- Schritte 1-3: Namen für Innersubjektfaktor definieren und Anzahl Messungen angeben, Hinzufügen klicken, dann Definieren klicken.
- Schritt 4: Die Variablen auf die Messungen zuordnen und anschliessend nach Bedarf Optionen anwählen
- Post-hoc-Tests für den Innersubjektfaktor (die Messwiederholung) können nicht über bei "Post Hoc" gewählt werden, sondern bei Optionen.
- Die roten, gestrichelten Boxen sind lediglich bei einem zusätzlichen Zwischensubjektfaktor relevant (Homogenitätstest, "Post Hoc"-Button). Beispiele wären: Bildungsniveau oder Geschlecht.
SPSS-Syntax
GLM Morgen Mittag Abend
/WSFACTOR=Tageszeit 3 Polynomial
/PLOT=PROFILE(Tageszeit)
/EMMEANS=TABLES(Tageszeit) COMPARE ADJ(BONFERRONI)
/PRINT=DESCRIPTIVE ETASQ HOMOGENEITY
/METHOD=SSTYPE(3)
/CRITERIA=ALPHA(.05)
/WSDESIGN=Tageszeit.
3.2. Mauchly-Test auf Sphärizität
Eine Voraussetzung für die Durchführung einer Varianzanalyse mit Messwiederholung ist die sogenannte "Compound symmetry": Diese ist gegeben, wenn die Stichprobenvarianzen der einzelnen Messzeitpunkte homogen und die Korrelationen zwischen jedem Paar von Messzeitpunkten identisch sind, wenn folglich homogene Stichprobenvarianzen und -korrelationen vorliegen.
Sphärizität ist eine etwas weniger restriktive Form der "Compound symmetry". Sphärizität liegt vor, wenn die Varianzen der Differenzen zwischen jeweils zwei Messzeitpunkten gleich sind. Dieser Test ist folglich erst ab drei Messzeitpunkten relevant (bei zwei Messzeitpunkten nur ein Paar). Um die Voraussetzung der Sphärizität zu überprüfen, wird der Mauchly-Test durchgeführt. Ist der Mauchly-Test nicht signifikant, so kann von Sphärizität ausgegangen werden. Wäre der Mauchly-Test aber signifikant, so läge keine Sphärizität vor.
Ist die Voraussetzung der Sphärizität nicht erfüllt, so werden die Freiheitsgrade der Signifikanztests angepasst, indem sie mit einem Korrekturfaktor Epsilon (ε) multipliziert werden. SPSS gibt einerseits das Epsilon nach Greenhouse-Geisser aus, andererseits das Epsilon nach Huynh-Feldt. Das erstere ist etwas restriktiver und wird daher bei stärkeren Verletzungen der Annahme der Sphärizität eingesetzt: Ist das Epsilon nach Greenhouse-Geisser < .75, so wird die Korrektur nach Greenhouse-Geisser verwendet. Ist das Epsilon nach Greenhouse-Geisser > .75, so wird die Korrektur nach Huynh-Feldt eingesetzt.

In SPSS wird der Test auf Sphärizität bei Durchführung einer Varianzanalyse mit Messwiederholung automatisch ausgegeben. Der Mauchly-Test in Abbildung 3 ist nicht signifikant (Mauchly-W(2) = .750, p = .154). Daher kann für das Beispiel von Sphärizität ausgegangen werden.
3.3. Ergebnisse der einfaktoriellen Varianzanalyse mit Messwiederholung
Deskriptive Statistiken
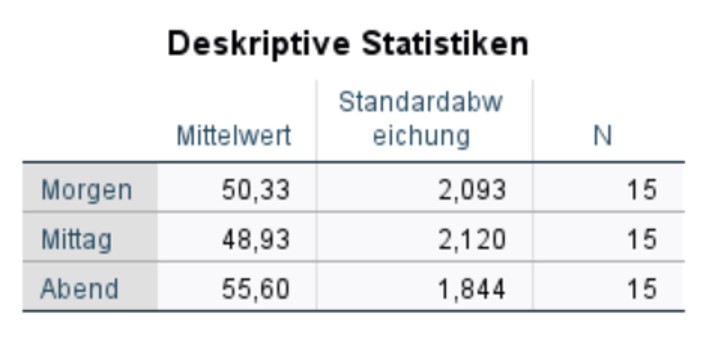
Die Tabelle in Abbildung 4 gibt die Mittelwerte, Standardabweichungen und Stichprobengrössen zu allen drei Messzeitpunkten wieder. Diese Informationen werden für die Berichterstattung verwendet.
Tests der Innersubjekteffekte
Die Tabelle "Tests der Innersubjekteffekte" (Abbildung 5) gibt den Signifikanztest für den sogenannten "Haupteffekt" der Messwiederholung aus. Ein Haupteffekt ist der direkte Effekt eines Faktors auf die abhängige Variable. Wie der Name der Tabelle betont, geht es bei Innersubjekteffekten um Unterschiede innerhalb von Personen, nicht zwischen Personen.
Da von Sphärizität ausgegangen werden kann, müssen die Freiheitsgrade nicht korrigiert werden. Das heisst, die Zeile "Sphärizität angenommen" wird verwendet. Muss eine Korrektur der Tests verwendet werden, so wird entsprechend die Zeile "Greenhouse-Geisser" oder "Huynh-Feldt" berichtet, je nachdem welche der beiden Korrekturen angebracht ist.
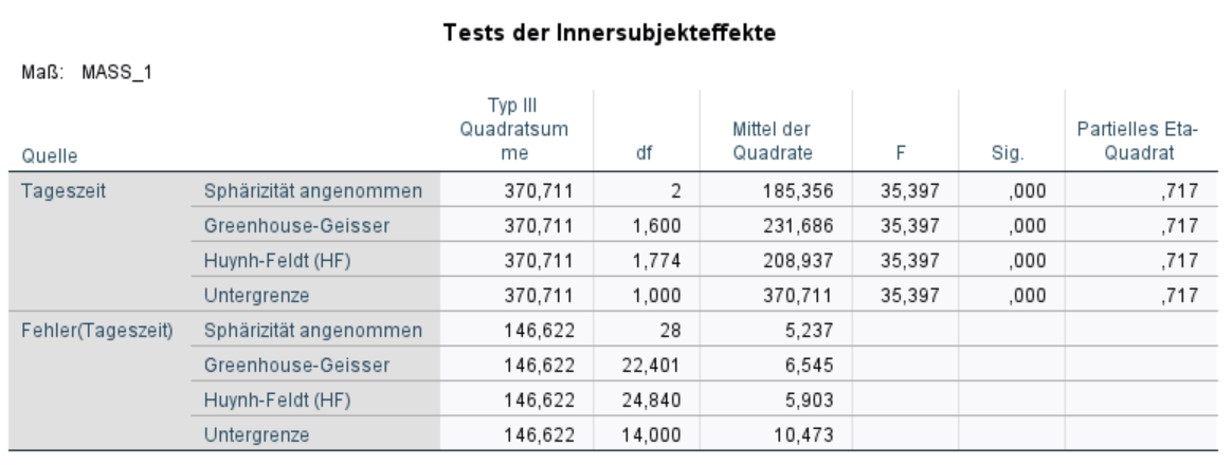
Abbildung 5 kann entnommen werden, dass die Tageszeit einen signifikanten Einfluss auf die Konzentrationsleistung hat (F(2,28) = 35.397, p < .001, ηp2 = .717). Es gibt also einen Haupteffekt der Tageszeit.
Das partielle Eta-Quadrat
Das partielle Eta-Quadrat (ηp2), das am rechten Rand der Tabelle in Abbildung 5 ausgegeben wird, ist ein Mass für die Effektgrösse: Es setzt die Varianz, die durch einen Faktor erklärt wird, in Bezug mit jener interessierenden Varianz, die noch nicht durch andere Faktoren im Modell erklärt wird. Das heisst, es wird ausschliesslich jene Variation betrachtet, welche im Fokus des Interesses steht und nicht bereits durch die anderen Faktoren im Modell erklärt wird. Das partielle Eta-Quadrat zeigt, welchen Anteil davon ein Faktor erklärt. Im Falle der einfaktoriellen Varianzanalyse mit Messwiederholung liegt das Interesse ausschliesslich auf der Varianz innerhalb der Personen (SSinnerhalb Personen = SSTreatment + SSResidual), weswegen sich das partielle Eta-Quadrat wie folgt berechnet:
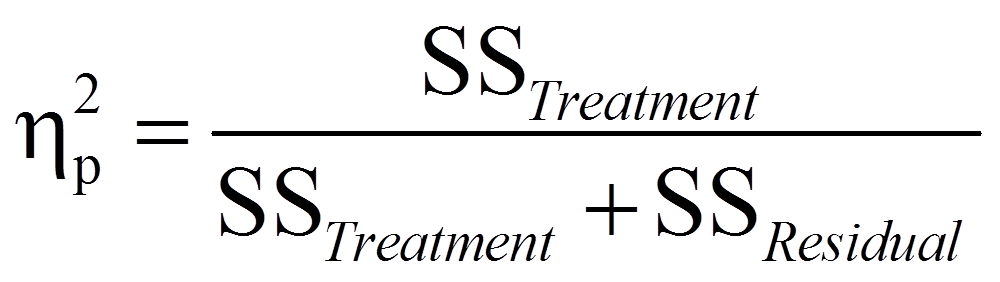
Im vorliegenden Beispiel beträgt das partielle Eta-Quadrat .717. Das heisst, es wird 71.7% der Variation der Konzentrationsfähigkeit durch die Tageszeit aufgeklärt.
Hinweis: Mehrfaktorielle Varianzanalyse mit Messwiederholung
Es ist möglich und oft auch sinnvoll, weitere Faktoren in ein Modell einzubeziehen, wie beispielsweise das Geschlecht, den Bildungsgrad oder, wenn verschiedene Trainings zu Konzentrationsfähigkeit angewandt worden wären, auch den Typ des Trainings. Bei den genannten Beispielen handelt es sich um sogenannte "Zwischensubjektfaktoren", also Faktoren, die zwischen den Personen variieren und innerhalb der Person konstant sind. Werden solche Faktoren in einer Analyse mit Messwiederholung verwendet, so muss der Levene-Test auf Varianzhomogenität durchgeführt werden (siehe einfaktorielle Varianzanalyse). Im SPSS-Output findet sich zusätzlich eine Tabelle mit den "Tests der Zwischensubjekteffekte", welche die F-Tests dieser Faktoren enthält. In der Tabelle der "Tests der Innersubjekteffekte" findet sich zudem eine Interaktion der Zwischensubjektfaktoren und der Messwiederholung.
3.4. Post-hoc-Tests
Multiples Testen
Obwohl der F-Test zeigt, dass ein Haupteffekt der Tageszeit besteht, muss anhand von Post-hoc-Tests geklärt werden, zwischen welchen Messzeitpunkten signifikante Unterschiede bezüglich der Konzentrationsfähigkeit bestehen.
Bei der Berechnung von Post-hoc-Tests wird im Prinzip für jede Kombination von zwei Mittelwerten ein t-Test durchgeführt. Im aktuellen Beispiel mit drei Gruppen sind dies 3 Tests. Multiple Tests sind jedoch problematisch, da der Alpha-Fehler (die fälschliche Ablehnung der Nullhypothese) mit der Anzahl der Vergleiche steigt. Wird nur ein t-Test mit einem Signifikanzlevel von .05 durchgeführt, so beträgt die Wahrscheinlichkeit des Nicht-Eintreffens des Alpha-Fehlers 95%. Werden jedoch drei solcher Paarvergleiche vorgenommen, so beträgt die Nicht-Eintreffens-Wahrscheinlichkeit des Alpha-Fehlers (.95)3 = .857. Um die Wahrscheinlichkeit des Eintreffens des Alpha-Fehlers zu bestimmen, wird 1 - .857 = .143 gerechnet. Die Wahrscheinlichkeit des Eintreffens des Alpha-Fehlers liegt somit bei 14.3%. Diese Fehlerwahrscheinlichkeit wird als "Familywise Error Rate" bezeichnet.
Um dieses Problem zu beheben kann zum Beispiel die Bonferroni-Korrektur angewandt werden. Hierbei wird α durch die Anzahl der Paarvergleiche dividiert. Im hier aufgeführten Fall ist dies .05/3 = .017. Das heisst, jeder Test wird gegen ein Niveau von .017 geprüft. Die Bonferroni-Korrektur führt zu eher konservativen Tests bezüglich des Alpha-Fehlers, während andere Korrekturen weniger konservativ sind. SPSS bietet eine grosse Auswahl an möglichen Korrekturen (vgl. Klicksequenz in Abbildung 2).
Post-hoc-Tests für das vorliegende Beispiel
Abbildung 6 zeigt die Ergebnisse der Post-hoc-Tests mit Bonferroni-Korrektur. In der Abbildung sind 6 und nicht nur 3 Tests aufgeführt, da SPSS jeden Test in beide Richtungen durchführt. Dies ist jedoch nicht notwendig, da das Testergebnis nicht von der Richtung abhängig ist. Ferner gilt es zu beachten, dass die p-Werte bereits von SPSS Bonferroni-korrigiert wurden und darum nun gegen .05 geprüft werden dürfen.
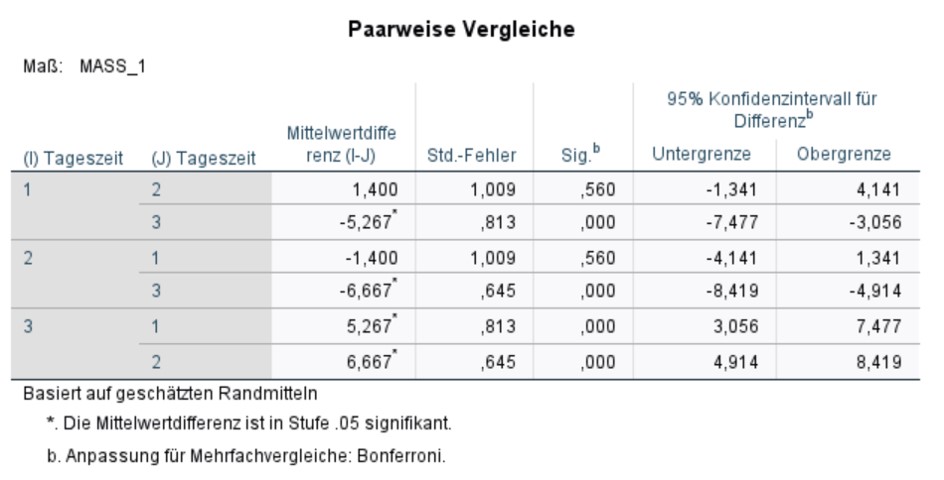
Es wird ersichtlich, dass sich die Konzentrationsfähigkeit morgens und abends (p < .001) sowie mittags und abends (p < .001) signifikant voneinander unterscheidet.
3.5. Profildiagramm
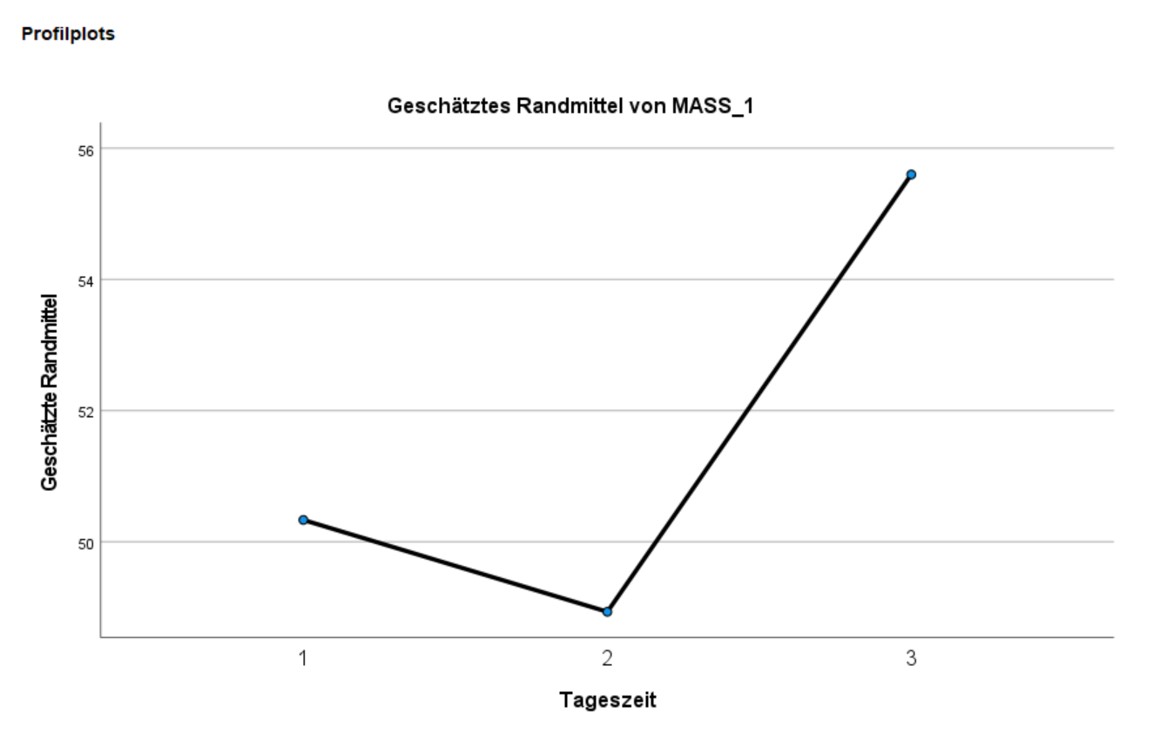
Das Profildiagramm in Abbildung 7 illustriert die Ergebnisse der Varianzanalyse. Während dieses Diagramm hier wenig zusätzliche Informationen beinhaltet, sind analoge Diagramme im Falle der mehrfaktoriellen Varianzanalyse äusserst hilfreich für die Interpretation der Ergebnisse.
3.6. Berechnung der Effektstärke
Um die Bedeutsamkeit eines Ergebnisses zu beurteilen, werden Effektstärken berechnet. Im Beispiel sind zwar einige der Mittelwertsunterschiede signifikant, doch es stellt sich die Frage, ob sie gross genug sind, um als bedeutend eingestuft zu werden.
Es gibt verschiedene Arten die Effektstärke zu messen. Zu den bekanntesten zählen die Effektstärke von Cohen (d) und der Korrelationskoeffizient (r) von Pearson. Der Korrelationskoeffizient eignet sich sehr gut, da die Effektstärke dabei immer zwischen 0 (kein Effekt) und 1 (maximaler Effekt) liegt. Wenn sich jedoch die Gruppen hinsichtlich ihrer Grösse stark unterscheiden, wird empfohlen, d von Cohen zu wählen, da r durch die Grössenunterschiede verzerrt werden kann.
Da SPSS das partielle Eta-Quadrat ausgibt, wird dieses hier in die Effektstärke f nach Cohen (1992) umgerechnet. In diesem Fall befindet sich die Effektstärke immer zwischen 0 und unendlich.
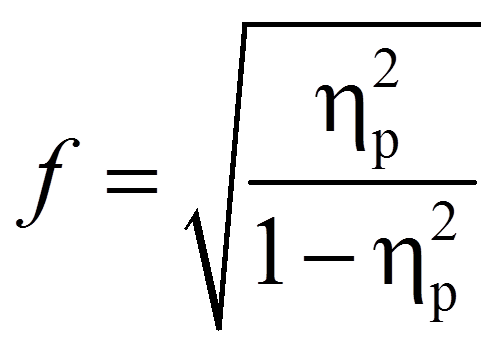
mit
|
|
= | Effektstärke nach Cohen |
|
|
= | Partielles Eta-Quadrat |
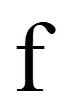
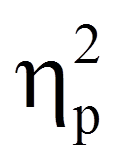
Für das obige Beispiel ergibt das folgende Effektstärke:
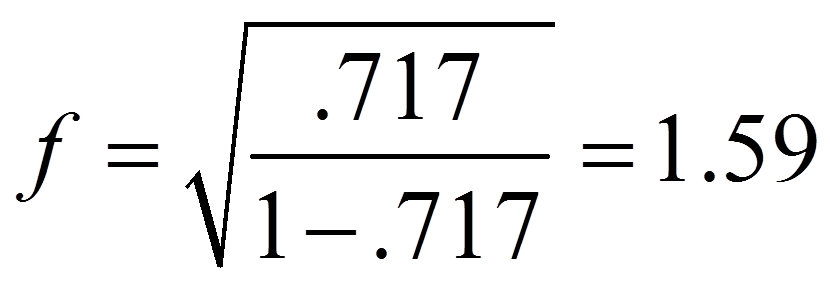
Um zu beurteilen, wie gross dieser Effekt ist, kann man sich an der Einteilung von Cohen (1988) orientieren:
f = .10 entspricht einem schwachen Effekt
f = .25 entspricht einem mittleren Effekt
f = .40 entspricht einem starken Effekt
Damit entspricht die Effektstärke von 1.59 einem starken Effekt.
3.7. Eine typische Aussage
Eine Varianzanalyse mit Messwiederholung (Sphärizität angenommen: Mauchly-W(2) = .750, p = .154) zeigt, dass die Konzentrationsfähigkeit mit der Tageszeit zusammenhängt (F(2,28) = 35.397, p < .001, ηp2 = .717, n = 15). Bonferroni-korrigierte paarweise Vergleiche zeigen, dass die Konzentrationsfähigkeit abends (M = 55.6, SD = 1.84) signifikant höher ist als morgens (M = 50.33, SD = 2.09) und mittags (M = 48.9, SD = 2.12). Zwischen diesen beiden Messzeitpunkten unterscheidet sich die Konzentrationsfähigkeit hingegen nicht. Die Effektstärke f nach Cohen (1988) liegt bei 1.59 und entspricht einem starken Effekt.