Friedman-Test
Seiteninhalt
- Quick Start
- 1. Einführung
- 1.1. Beispiele für mögliche Fragestellungen
- 1.2. Voraussetzungen des Friedman-Tests
- 2. Grundlegende Konzepte
- 2.1. Beispiel einer Studie
- 2.2. Berechnung der Teststatistik
- 3. Der Friedman-Test mit SPSS
- 3.1. SPSS-Befehle
- 3.2. Ergebnisse des Friedman-Tests
- 3.3. Post-hoc-Tests
- 3.4. Berechnung der Effektstärke
- 3.5. Eine typische Aussage
Quick Start
|
Wozu wird der Friedman-Test verwendet? |
1. Einführung
Der Friedman-Test für abhängige Stichproben testet, ob sich die zentralen Tendenzen mehrerer abhängiger Stichproben unterscheiden. Der Friedman-Test wird verwendet, wenn die Voraussetzungen für eine Varianzanalyse nicht erfüllt sind.
Von "abhängigen Stichproben" wird gesprochen, wenn ein Messwert in einer Stichprobe und ein bestimmter Messwert in einer anderen Stichprobe sich gegenseitig beeinflussen. In drei Situationen ist dies der Fall:
- Messwiederholung: Die Messwerte stammen von der gleichen Person, zum Beispiel bei einer Messung vor einem Treatment, während einem Treatment und nach einem Treatment oder wenn verschiedene Treatments auf die gleiche Person angewendet werden und verglichen werden sollen.
- Natürliche Paare: Die Messwerte stammen von verschiedenen Personen, welche irgendwie zusammengehören (z.B.: Ehefrau – Ehemann – Paartherapeut, Psychologe – Patient, Anwalt – Klient oder Zwillinge).
- Matching: Die Messwerte stammen von verschiedenen Personen, die einander zugeordnet wurden, zum Beispiel aufgrund eines vergleichbaren Werts auf einer Drittvariablen (die nicht im Zentrum der Untersuchung steht).
Der Friedman-Test ist das nichtparametrische Äquivalent der einfaktoriellen Varianzanalyse mit Messwiederholung und wird angewandt, wenn die Voraussetzungen für ein parametrisches Verfahren nicht erfüllt sind. Nicht-parametrische Verfahren sind auch bekannt als "voraussetzungsfreie Verfahren", weil sie geringere Anforderungen an die Verteilung der Messwerte in der Grundgesamtheit stellen. So müssen die Daten nicht normalverteilt sein und die abhängige Variable muss lediglich ordinalskaliert sein. Auch bei kleinen Stichproben und Ausreissern kann ein Friedman-Test berechnet werden.
Die Fragestellung des Friedman-Tests wird oft so verkürzt:
"Unterscheiden sich die zentralen Tendenzen einer Variable zwischen mehreren abhängigen Gruppen, respektive Messzeitpunkten?"
1.1. Beispiele für mögliche Fragestellungen
- Fünf verschiedene Methoden zur Diagnostik der Schwangerschaftsdauer werden an 10 Frauen getestet. Unterscheiden sich die Vorhersagen?
- In einem Eishockey-Team wird ein neues Krafttraining eingeführt. Die Muskelmasse der Spieler wird vor dem Training, direkt danach, sowie drei Monate später erhoben. Wie entwickelt sich der Muskelaufbau der Eishockey-Spieler?
- In einer Studie zu Aggressivität in Kinderkrippen werden Mütter, Väter und Krippenpersonal zum Verhalten der Kinder befragt. Unterscheiden sich die Beurteilungen?
- Um den Effekt vier verschiedener Therapiemethoden zu prüfen, werden 92 Personen im geschlossenen Strafvollzug untersucht. Da vermutet wird, dass die Intelligenz einen Einfluss auf den Therapieerfolg haben könnte, werden vorab Vierergruppen von Probanden vergleichbarer Intelligenz gebildet. Die vier Personen in jeder Gruppe werden zufällig so auf die vier Treatments verteilt, dass an jedem Treatment je eine Person aus jeder Gruppe teilnimmt. Weisen die vier Therapiemethoden unterschiedliche Effekte auf?
1.2. Voraussetzungen des Friedman-Tests
| ✓ | Die abhängige Variable ist mindestens ordinalskaliert |
| ✓ | Es liegen verbundene Stichproben vor, aber die verbundenen "Gruppen" von Messwerten sind unabhängig voneinander (z.B. die verschiedenen Mutter-Vater-Kind-Triaden sind voneinander unabhängig) |
2. Grundlegende Konzepte
2.1. Beispiel einer Studie
Zehn Mitarbeitende eines Unternehmens nehmen an einer Verkaufsschulung teil. Es soll untersucht werden, ob sich die Schulung auf die Verkaufszahlen auswirkt. Daher werden für jeden Mitarbeitenden die Verkaufszahlen vor der Schulung, im ersten, zweiten, dritten und vierten Monat danach erhoben. Zeigen sich Unterschiede zwischen den Messzeitpunkten? Da die Stichprobe klein ist (n = 10) wird ein Friedman-Test durchgeführt.
Der zu analysierende Datensatz enthält neben einer Identifikationsnummer der Mitarbeitenden (ID) die fünf Verkaufszahlen (Vortest, Monat_1, Monat_2, Monat_3, Monat_4).
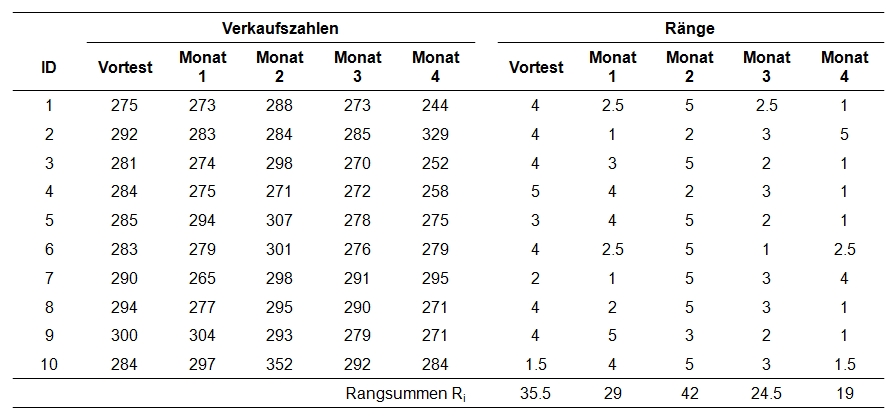
Der Datensatz kann unter Quick Start heruntergeladen werden.
2.2. Berechnung der Teststatistik
Berechnen der Teststatistik
Der Friedman-Test basiert auf der Idee der Rangierung der Daten. Das heisst, es wird nicht mit den Messwerten selbst gerechnet, sondern diese werden durch Ränge ersetzt, mit welchen der eigentliche Test durchgeführt wird. Damit beruht die Berechnung des Tests ausschliesslich auf der Ordnung der Werte (grösser als, kleiner als). Die absoluten Abstände zwischen den Werten werden nicht berücksichtigt.
Innerhalb von jedem Mitarbeitenden werden den einzelnen Messzeitpunkten Ränge zugewiesen (siehe Spalten "Ränge" in Abbildung 1). Im vorliegenden Beispiel sind dies die Ränge 1 bis 5, da fünf Messungen stattgefunden haben. Der Mitarbeiter 1 hat beispielsweise die Werte 275, 273, 288, 273 und 244. Dem niedrigsten Wert wird grundsätzlich der Rang 1 zugewiesen, dem zweitniedrigsten der Rang 2 etc. Kommt ein Messwert mehrfach vor (engl. "ties"), so werden sogenannte "verbundene Ränge" gebildet. Wenn beispielsweise Rang 4 und 5 beide die gleichen Messwerte aufweisen, wird aus diesen beiden der Mittelwert gebildet ((4 + 5)/2 = 4.5) und die Ränge 4 und 5 werden neu beide mit dem Rang 4.5 versehen. Im Beispiel gibt es Messwerte, die mehrfach auftauchen: Beim Mitarbeitenden 1 kommt der Wert 273 zweimal vor. Dies ist für den Mitarbeitenden 1 der zweitniedrigste Wert und entspricht damit den potenziellen Rängen 2 bis 3. Nun wird der Durchschnitt dieser Ränge ((2+3)/2 = 2.5) berechnet. Der Wert 273 erhält somit den Rang 2.5 (siehe Zeile für den ersten Mitarbeitenden in Abbildung 1).
Schliesslich werden aus diesen ermittelten Rängen sogenannte "Rangsummen" für jeden Messzeitpunkt gebildet (siehe Abbildung 1, Zeile "Rangsummen"). Hierfür werden lediglich die Ränge des jeweiligen Messzeitpunktes aufsummiert. Sind diese Rangsummen für die Messzeitpunkte unterschiedlich hoch, so ist dies ein Hinweis auf Unterschiede zwischen den Messzeitpunkten.
Anschliessend wird die von Friedman entwickelte Teststatistik berechnet:
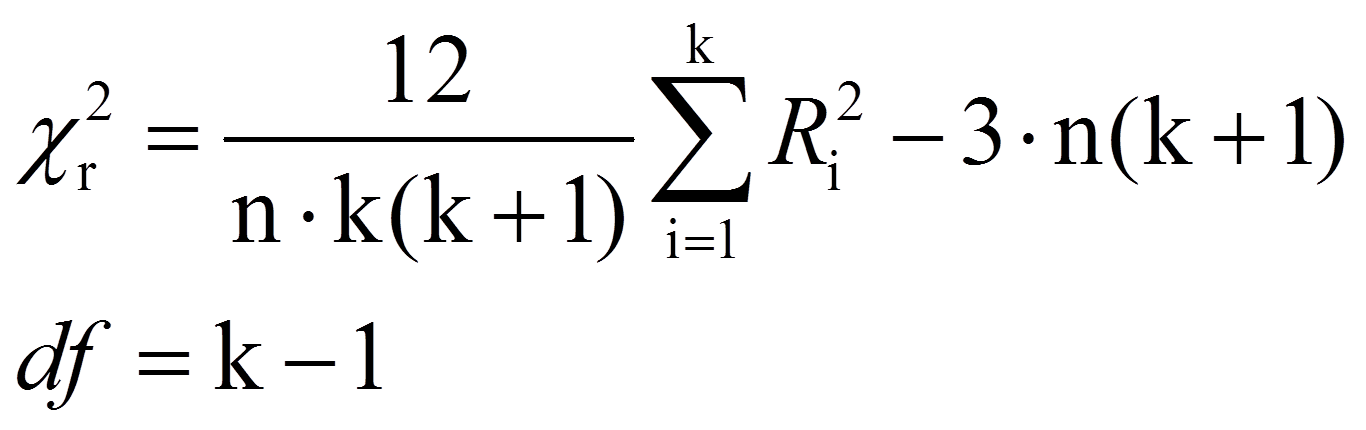
mit
| = | Anzahl Treatments oder Messwiederholungen | |
| = | Anzahl Probanden | |
| = | Rangsumme von Treatment oder Messzeitpunkt i |
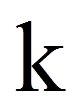
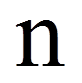
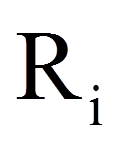
Für das vorliegende Beispiel ergibt dies:

Liegen verbundene Ränge vor, so muss die Prüfgrösse korrigiert werden:
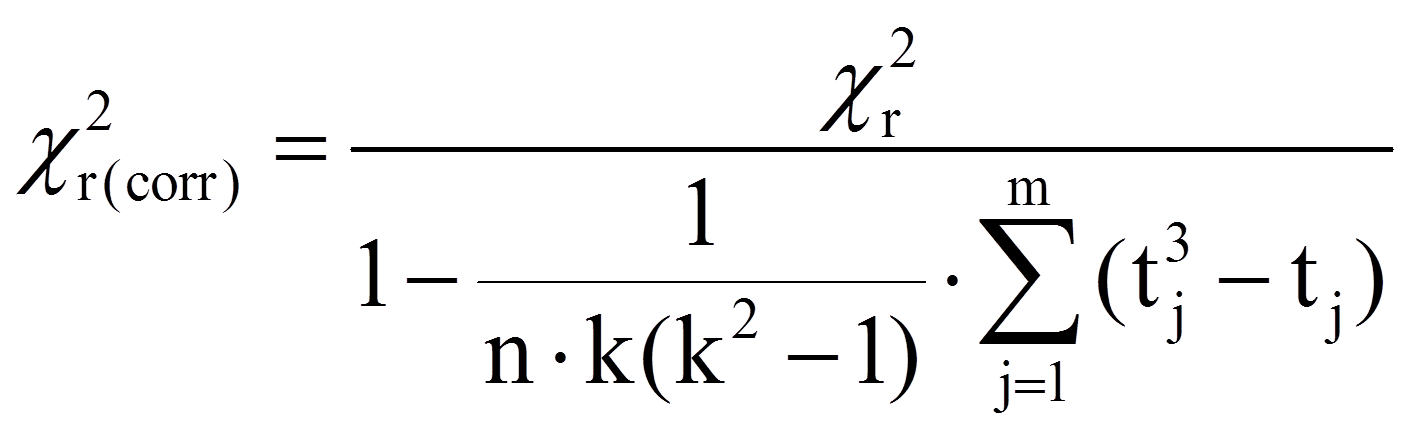
mit
|
|
= | Anzahl Probanden |
|
|
= | Anzahl Treatments oder Messwiederholungen |
|
|
= | Anzahl Fälle, in denen verbundene Ränge aufgetreten sind |
|
|
= | Anzahl Rohdatenwerte, die im j-ten Rangplatz stehen |
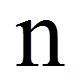
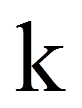
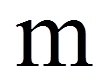
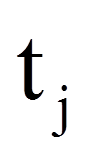
Da beim Beispiel verbundene Ränge vorliegen, muss die Korrekturformel angewandt werden. Ein Blick auf Abbildung 1 zeigt, dass an drei Stellen (daher m = 3) jeweils zwei verbundene Ränge (daher t1 = t2 = t3 = 2) vorkommen (bei Mitarbeitenden 1, 6 und 10). Dies ergibt:
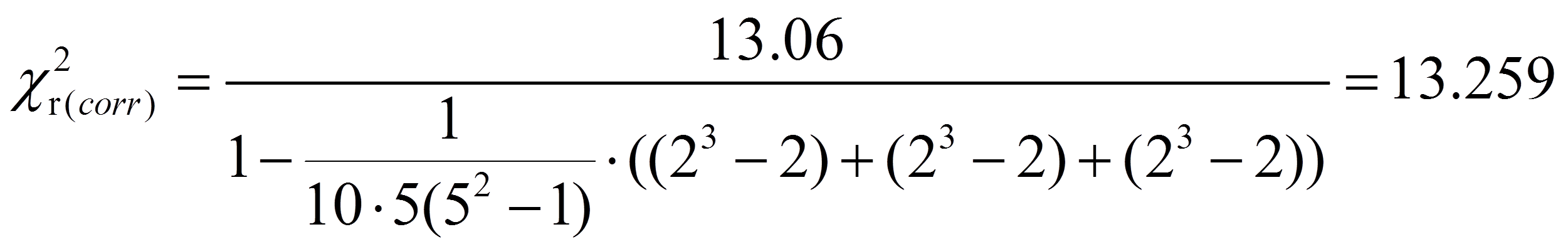
Signifikanz der Teststatistik
Der berechnete Wert muss nun auf Signifikanz geprüft werden. Dazu wird die Teststatistik mit dem kritischen Wert der durch die Freiheitsgrade (df) bestimmten Chi-Quadrat-Verteilung verglichen. Dieser kritische Wert kann Tabellen entnommen werden. Abbildung 2 zeigt einen Auszug.
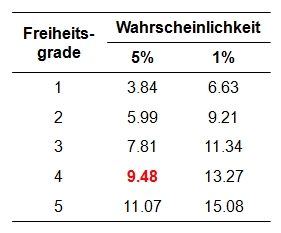
Für das vorliegende Beispiel beträgt der kritische Wert 9.48 bei df = 4 und α = .05 (siehe Abbildung 2). Ist der Wert der Teststatistik höher als der kritische Wert, so ist der Unterschied signifikant. Dies ist für das Beispiel der Fall (13.259 > 9.48). Es kann also davon ausgegangen werden, dass sich die Verkaufszahlen zu den verschiedenen Messzeitpunkten unterscheiden (Chi-Quadrat(4) = 13.26, p = .010, n = 10).
3. Der Friedman-Test mit SPSS
3.1. SPSS-Befehle
SPSS-Menü: Analysieren > Nichtparametrische Tests > Klassische Dialogfelder > K verbundene Stichproben

- Abbildung 3: Klicksequenz in SPSS
Hinweis
- Wird Quartile angewählt, so wird der Median für jeden Messzeitpunkt / jedes Treatment ausgegeben. Die ist für die Berichterstattung hilfreich.
SPSS-Syntax
NPAR TESTS
/FRIEDMAN=Vortest Monat_1 Monat_2 Monat_3 Monat_4
/STATISTICS DESCRIPTIVES QUARTILES
/MISSING LISTWISE.
3.2. Ergebnisse des Friedman-Tests
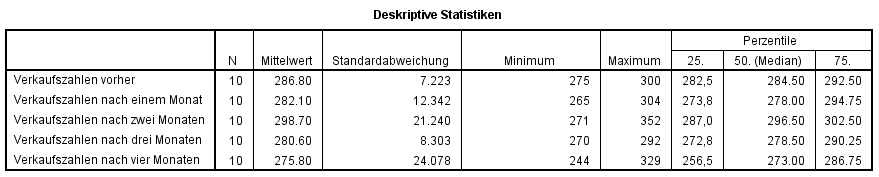
Für die Berichterstattung wird der Median aus Abbildung 4 abgelesen. Die Mediane zeigen keine klare Entwicklung über die Messzeitpunkte.
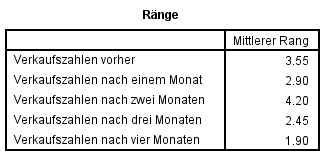
Abbildung 5 lassen sich die mittleren Ränge der einzelnen Messzeitpunkte ablesen. Es lässt sich auf den ersten Blick keine einfach zu interpretierende Ordnung entdecken.

Wie Abbildung 6 entnommen werden kann, unterscheiden sich die Verkaufszahlen der einzelnen Messzeitpunkte signifikant (Chi-Quadrat(4) = 13.26, p = .010, n = 10). Allerdings lässt sich aufgrund dieses Tests nicht bestimmen, welche der fünf Messzeitpunkte sich signifikant voneinander unterscheiden. Es ist denkbar, dass sich lediglich ein Paar signifikant unterscheidet und zwischen den übrigen keine signifikanten Unterschiede vorliegen.
3.3. Post-hoc-Tests
Obwohl der Friedman-Test zeigt, dass tatsächlich Unterschiede zwischen den Messzeitpunkten vorliegen, müssen Post-hoc-Tests durchgeführt werden, um zu bestimmen, welche Messzeitpunkte sich signifikant unterscheiden.
Dunn-Bonferroni-Tests
Post-hoc-Tests können einfach durchgeführt werden, sofern der Friedman-Test nicht über die übersichtlicheren "Klassische Dialogfelder", sondern über die neueren Dialoge durchgeführt wurde: Analysieren > Nichtparametrische Tests > Verbundene Stichproben (siehe Abbildunge 7). Bei den derart durchgeführten Post-hoc-Tests handelt es sich um Dunn-Bonferroni-Tests.
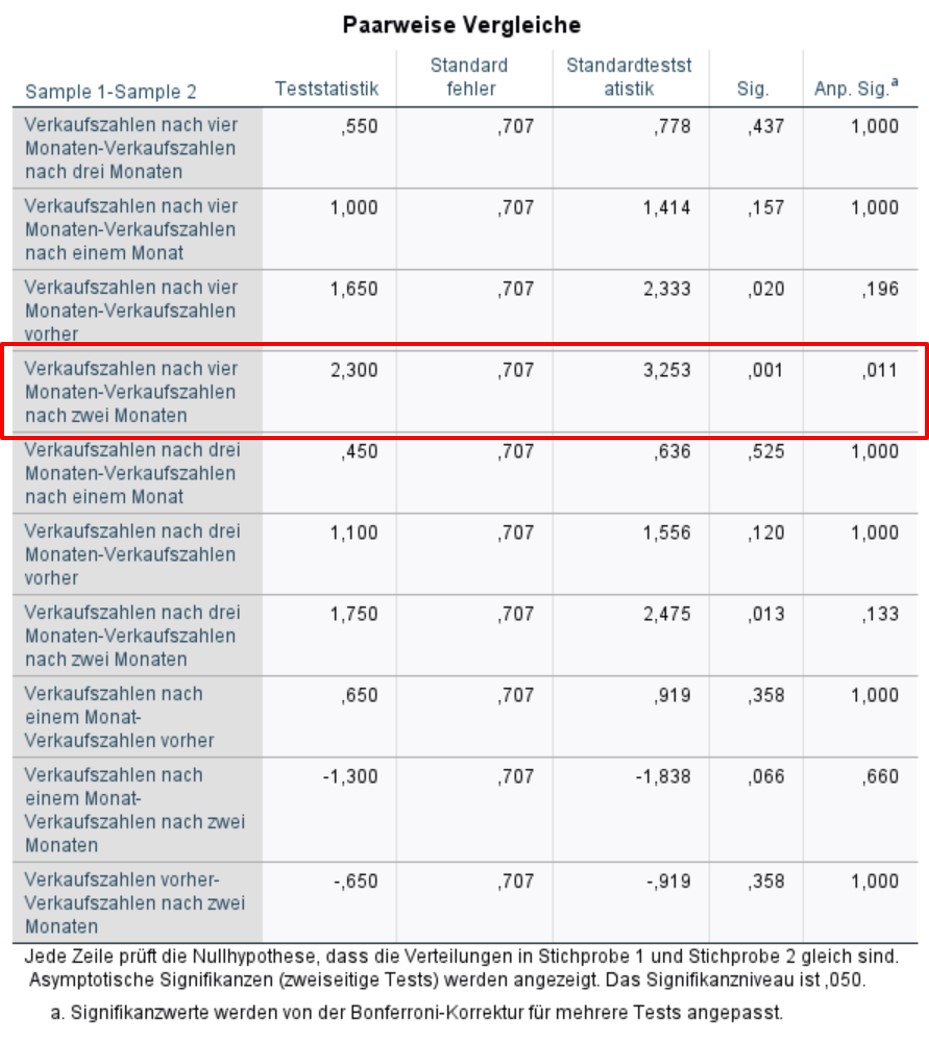
Gemäss den über den SPSS-Output erzeugten Dunn-Bonferroni-Tests (Abbildung 8) ist der Unterschied zwischen den Verkaufszahlen nach zwei und nach vier Monaten signifikant (z = 2.3, p = .011). Ein Blick auf die deskriptiven Statistiken in Abbildungen 4 und 5 zeigt, dass es sich hierbei um die Gruppen mit den höchsten (Monat 2) und den tiefsten Verkaufszahlen (Monat 4) handelt.
3.4. Berechnung der Effektstärke
Um die Bedeutsamkeit eines Ergebnisses zu beurteilen, werden Effektstärken berechnet. Im Beispiel sind zwar einige der Mittelwertsunterschiede signifikant, doch es stellt sich die Frage, ob sie gross genug sind, um als bedeutend eingestuft zu werden.
Es gibt verschiedene Arten die Effektstärke zu messen. Zu den bekanntesten zählen die Effektstärke von Cohen (d) und der Korrelationskoeffizient (r) von Pearson. Der Korrelationskoeffizient eignet sich sehr gut, da die Effektstärke dabei immer zwischen 0 (kein Effekt) und 1 (maximaler Effekt) liegt. Wenn sich jedoch die Gruppen hinsichtlich ihrer Grösse stark unterscheiden, wird empfohlen, d von Cohen zu wählen, da r durch die Grössenunterschiede verzerrt werden kann.
Da aufgrund von Post-hoc-Tests genauer eingegrenzt wurde, wo der Unterschied liegt, das heisst, welche Gruppen sich unterscheiden, ist oft weniger die Effektstärke des Friedman-Tests von Interesse, sondern eher die Effektstärke der einzelnen Vergleiche. Das bedeutet, dass die Effektstärke des Dunn-Bonferroni-Tests berechnet wird, die der Effektstärke eines Rangsummentests entspricht.
Zur Berechnung des Korrelationskoeffizienten r werden der z-Wert und die Stichprobengrösse (n) verwendet, die dem SPSS-Output (Abbildungen 7 und 8) entnommen werden können:

Für das obige Beispiel ergibt das folgende Effektstärke (mit den Werten des Dunn-Bonferroni-Tests):

Zur Beurteilung der Grösse des Effektes dient die Einteilung von Cohen (1992):
r = .10 entspricht einem schwachen Effekt
r = .30 entspricht einem mittleren Effekt
r = .50 entspricht einem starken Effekt
Damit entspricht die Effektstärke von .73 einem starken Effekt.
3.5. Eine typische Aussage
Obwohl sich die Verkaufszahlen zwischen den fünf Messzeitpunkten unterscheiden (Friedman-Test: Chi-Quadrat(4) = 13.26, p = .010, n = 10), ist das Ergebnis schwierig zu interpretieren. Es lässt sich kein interpretierbares Muster über die Zeit hinweg erkennen (zum Beispiel eine Abnahme, Zunahme oder Stagnation). Anschliessend durchgeführte Post-hoc-Tests (Dunn-Bonferroni-Tests) zeigen, dass sich Monat 2 und Monat 4 signifikant unterscheiden (z = 2.3, pangepasst = .011, Effektstärke nach Cohen (1992): r = .73), wobei Monat 2 die höchsten Verkaufszahlen aufweist und Monat 4 die geringsten. Da die Schulung eine Steigerung der Verkaufszahlen zum Ziel hatte, muss an dieser Stelle gefolgert werden, dass sich die gewünschte Wirkung nicht zeigt.